Abstract
We are living in a data-driven society. Big Data and the Internet of Things are popular terms. Governments, universities and the private sector make great investments in collecting and storing data and also extracting new knowledge from these data banks. Technological enthusiasm runs throughout political discourses. “Algorithmic regulation” is defined as a form of data-driven governance. Big Data shall offer brand new opportunities in scientific research. At the same time, political criticism of data storage grows because of a lack of privacy protection and the centralization of data in the hands of governments and corporations. Calls for data-driven dynamic regulation have existed in the past. In Chile, cybernetic development led to the creation of Cybersyn, a computer system that was created to manage the socialist economy under the Allende government 1971–1973.
My contribution will present this Cybersyn project created by Stafford Beer. Beer proposed the creation of a “liberty machine” in which expert knowledge would be grounded in data-guided policy. The paper will focus on the human–technological complex in society. The first section of the paper will discuss whether the political and social environment can completely change the attempts of algorithmic regulation. I will deal specifically with the development of technological knowledge in Chile, a postcolonial state, and the relationship between citizens and data storage in a socialist state. In a second section, I will examine the question of which measures can lessen the danger of data storage regarding privacy in a democratic society. Lastly, I will discuss how much data-driven governance is required for democracy and political participation. I will present a second case study: digital participatory budgeting (DPB) in Brazil.
Keywords: Cybersyn; human–technological complex, data-driven complex; data-driven society; postcolonial history; socialism
Introduction
Technological enthusiasts promote a process of building a global information economy, once characterized by Bill Gates as “friction-free capitalism” (Mosco 2016). Big Data and cloud computing create a global culture of knowledge. Information production accelerates in networks that link data centers, devices, organizations and individuals. It defines the global expansion of networked data centers controlled by a handful of companies. The cloud and Big Data power informational capitalism and enable a dominant way of knowing (Mosco 2016). Data collection, data generation, and algorithmic governance are important topics in research, the economy and politics. According to Tim O’Reilly, developments in data collection and storage make governments more efficient and adaptive. He defines “algorithmic regulation”, a form of data-driven governance (O’Reilly 2013). Big Data will offer brand new opportunities in scientific research. At the same time, political criticism of data storage grows because of a lack of privacy protection and the centralization of data in the hands of governments and corporations. This discussion is now common in our society. Furthermore, I suggest that technological development is part of a complex pattern of factors forming our society. This human–technological complex will be the main point of discussion.
It is necessary to put Big Data and cloud computing in the context of political economy, society, and culture, i.e., the human–technological complex or social–technological complex. In our society, most developments in information technology aim to strengthen capitalism, although the world of information technology (IT) is a turbulent one. However, Big Data, cloud computing, and algorithmic regulation have deep historical roots (Medina 2015). A closer look at the past might show us how technological development could work with different social, economic, and political prerequisites. The history of cybernetics holds lessons for these present-day problems.
This contribution will deal with the following questions:
(1) Can a political environment completely change the attempts of algorithmic regulation?
(2) Which measures can weaken the dangers of data storage in a democratic society?
(3) How much data-driven governance do democracy and political participation need?
First, I will look at the term Big Data and its definition. Next, I will explore how a technological system built in Chile during the 1970s — Project Cybersyn — addressed issues similar to those we currently face in areas such as Big Data and algorithmic regulation. The paper will give an overview of how algorithmic governance can be completely different in a political, geographic and historical context different from that of northern capitalistic states. Realizing that technological investigation depends on social conditions, we must look at the factors that concretely differ.
One has to keep in mind that the Cybersyn project has been discussed little in scientific discourses since being destroyed in 1973. Only one great monography deals with project Cybersyn in detail: Eden Medina published her study “Cybernetic Revolutionaries” in 2011. She also published diverse papers on single aspects of the topic. Some papers and books of Raul Espejo, the Chilean informatic who was part of the team that developed Cybersyn, also support further research on the project (Espejo and Reyes 2011) Technological development is part of a complex pattern of factors forming a society’s technological complex. Nevertheless, a democratic society or a socialist government does not automatically guarantee responsible handling of stored data. Regarding this fact, I will discuss measures that might secure responsible handling of data and the possibility to handle Big Data in a responsible and democratic way. Finally, I will deal with the relationship between the political participation of people and the technological development of a social–technological complex. As an example of civic participation, I chose participatory budgeting in Brazil. I chose this example because I found some political similarities to the case of Chile at a local level during my research. In the 1990s, the city of Porto Alegre in southern Brazil won international renown with its innovative policies. The centerpiece of the new policies involved the population in planning the city budget, participatory budgeting. The new method of drawing up the budget radically altered the relationship between the city administration and civil society. In the last few years, so-called digital participatory budgets were installed in different cities. Digital participatory budgeting (DPB) is an online space for discussions with society on local budget allocation issues and priorities. Such platforms exist both as integral parts of face-to-face participatory budgeting and as exclusively digital experiences (Matheus et al. 2010). In this last section, I will discuss the role of digital support in the participatory budget. I will discuss how technological development and political activism can flow in a social–technological system.
Discussion
Definition of the Term Big Data
First, we must look at Big Data. The term has become ubiquitous but owing to a shared origin between academia, industry and the media there is no single unified definition. Various stakeholders provide diverse and often contradictory definitions. The lack of a consistent definition introduces ambiguity and hampers discourse relating to Big Data and algorithmic regulation (Ward and Barker 2013). To deal with the term in my discussion, I chose one of the most cited definitions that is included in a meta report from 2001 (Gartner). The report has since been co-opted as providing a key definition. Gartner proposed a threefold definition encompassing the so-called three Vs: volume, velocity and variety. This is a definition rooted in magnitude. The report remarks upon the increasing size of data, the increasing rate at which it is produced, and the increasing range of formats and representations employed (Laney 2001). Anecdotally, Big Data is predominantly associated with the two ideas of data storage and data analysis. These concepts are far from new. Therefore, we have to deal with the question of how Big Data is notably different from conventional data-processing techniques. For rudimentary insight as to the answer to this question one need look only at the term Big Data. Big implies significance, complexity, and challenge. Unfortunately, the word big also invites quantification and therein lies the difficulty in furnishing a unique definition (Ward and Barker 2013). Nevertheless, the most important characteristic of Big Data sets is the inability of data-processing application software to deal with them. The definition of Big Data does not only vary on volume, variety and velocity of the datasets, but also on the capacity of the organization, storing, management and employment of Big Data (Magoulas and Lorica 2009).
Despite the range and differences in diverse definitions, there are some points of similarity regarding the size, complexity and structure of Big Data.
The critical factors of Big Data are: (i) the volume of the datasets; (ii) the structure, behavior, and permutations of the datasets; (iii) the tools and techniques that are used to process a sizable or complex dataset (Ward and Barker 2013). This paper cannot provide an analysis of the available literature on Big Data analytics. There are various Big Data tools, methods and technologies with various applications and opportunities. There is one main problem: due to the rapid growth of Big Data, research on solutions to handle and extract value and knowledge from these datasets is necessary (Elgendy and Elgaral 2014). We are far from finding these solutions. I suggest that the storage and handling of Big Data sets is not only a technical problem but a political one.
I further suggest that Big Data is part of a “global culture of knowing” (Mosco 2016). Mentioned above, the “global culture of knowing” defines the global expansion of networked data centers controlled by a handful of companies in today’s capitalistic society as informational capitalism.
Obviously, data collection, data generation, and algorithmic governance are part of our society. Companies move their data into the cloud and collect masses of data from individuals who are storing traces of their identities in the cloud. The cloud is also used by the military in strategic planning as well as universities in transforming education. I already mentioned the danger of a lack of privacy protection and the centralization of data in the hands of governments and corporations. Even the scientific use of Big Data is critical, because of the volume and complexity of the datasets. At this point, I come to my first question:
Can a Political Environment Completely Change the Attempts of Algorithmic Regulation?
This section starts to discuss the complex relationship between technology and society.
Stated above, the history of Big Data, cloud computing and algorithmic regulation is a long one. Technological development not only exists in northern capitalistic states, but also in countries of the so-called “global south” under different social, economic and political prerequisites. Next, I explore how a technological system built in Chile during the 1970s — Project Cybersyn — addressed issues similar to those we currently face in areas such as Big Data, cloud computing, and algorithmic regulation.
If we move beyond technology and ideology, it is clear that we have already seen calls for data-driven dynamic regulation in the past. For example, algorithmic regulation is highly reminiscent of cybernetics, the interdisciplinary science that emerged in the aftermath of the Second World War. Cybernetics moved away from linear understandings of cause and effect and toward investigations of control through circular causality, or feedback. It influenced developments in areas as diverse as cognitive science, air defense, industrial management and urban planning. It also shaped ideas about governance (Medina 2015). Cybernetics can be defined as a scientific study of how humans, animals and machines control and communicate with each other. It is a transdisciplinary approach for exploring the structures constraints and possibilities of regulatory systems. Norbert Wiener, the famous Massachusetts Institute of Technology (MIT) mathematician, credited with coining the term cybernetics, defined cybernetics in 1948 as “the scientific study of control and communication in the animal and the machine” (Wiener 1948). The paper will show how the cybernetic project Cybersyn became a historical case for the early use of so-called groupware and early “internet” communication—an early form of the cloud.
The content of cybernetics varied according to geography and historical period. In the USA, early work on cybernetics was often associated with defense; in Britain, it was associated with understanding the brain (Medina 2015); in the Soviet Union cybernetics became a way to make the social sciences more scientific and also contributed to the use of computers in a highly centralized economy (Mosco 2016). In Chile, cybernetics led to the creation of a computer system some thought would further socialist revolution (Medina 2011).
A discussion of Project Cybersyn requires a treatment of Stafford Beer and the so-called viable system model (VSM) that he developed in the 1960s. Beer conducted groundbreaking work on the application of cybernetic concepts to the regulation of companies. He believed that cybernetics and operations research should drive action, whether in the management of a firm or governance on a national scale. Norbert Wiener, once told Stafford Beer that if he was the father of cybernetics, then Beer was the father of management cybernetics. Correspondence, invitations to conferences, meetings and friendships followed. Stafford was welcomed by many of the early pioneers and formed special bonds with his mentors, Warren McCulloch, Ross Ashby and Norbert Wiener (Leonard 2002).
For Beer, computers in the 1960s and 1970s presented exciting new opportunities for regulation. In 1967, he observed that computers could bring about structural transformations within organizations. Organizations, which could be firms as well as governments, were linked to new communications channels that enabled the generation and exchange of information and permitted dynamic decision making. Beer proposed the creation of a so-called liberty machine, a system that operated in close to real time, facilitated instant decision making, and shunned bureaucracy. The liberty machine should also prevent top-down tyranny by creating a distributed network of shared information. Expert knowledge would be grounded in data-guided policy instead of bureaucratic politics (Beer 1994).
Indeed, the liberty machine sounds a lot like the cloud, algorithmic regulation and data storage as we understand it today. Examining Beer’s attempt to construct an actual liberty machine in the context of political revolution — Project Cybersyn — further strengthens this comparison.
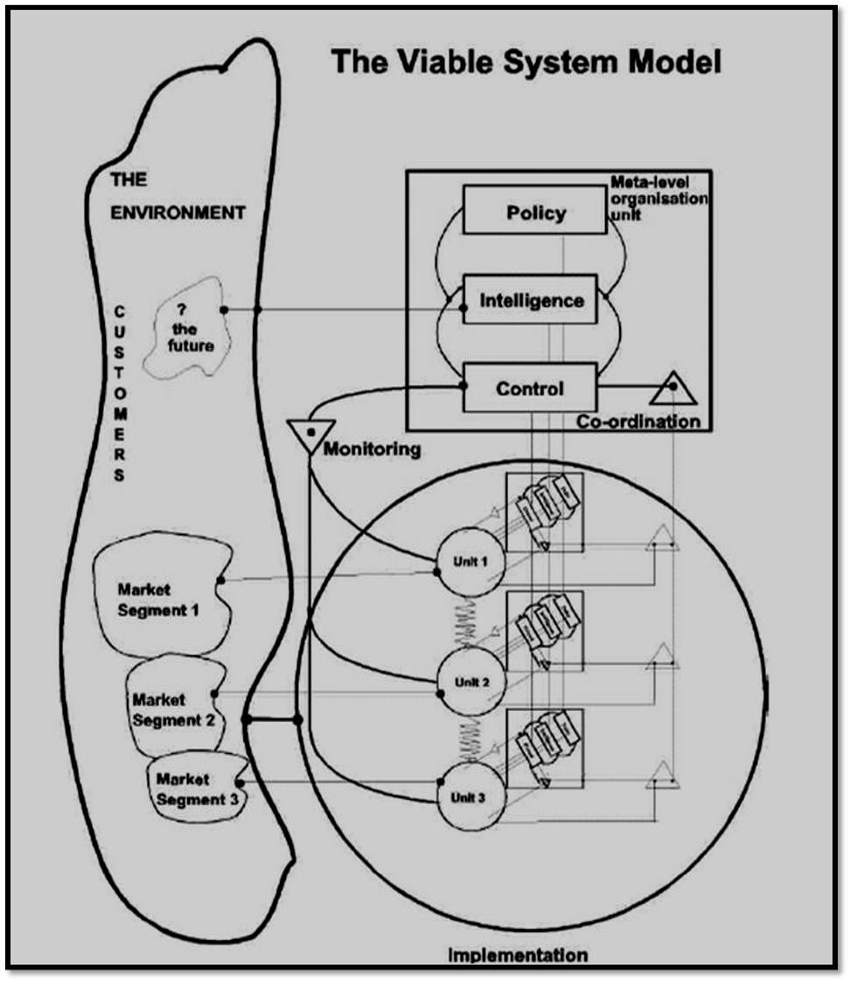
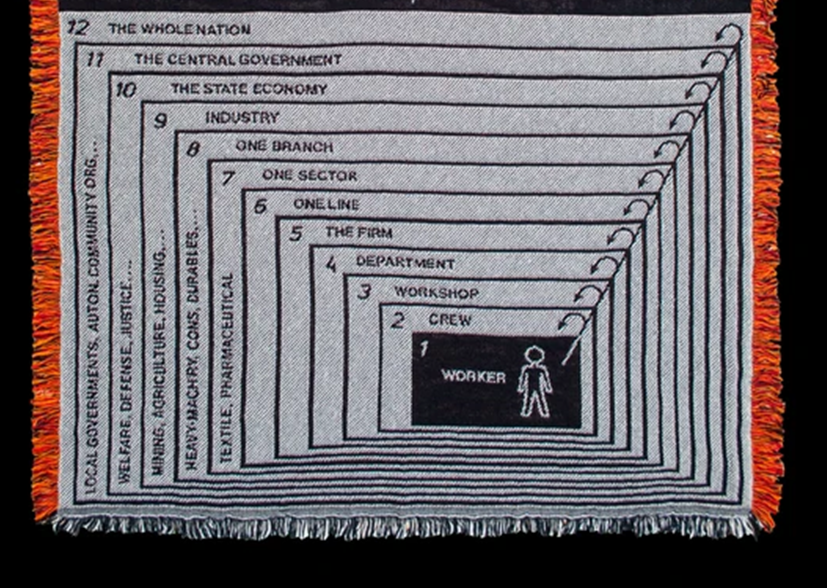
The VSM Stafford Beer developed in the 1960s is a model of the organizational structure of any autonomous system capable of reproducing itself. A viable system is defined as any system organized in such a way as to meet the demands of surviving in a changing environment. One of the prime features of systems that survive is that they are adaptable. The VSM expresses a model for a viable system, which is an abstracted cybernetic description that applies to any organization that is a viable system and capable of autonomy (Beer 1972). The VSM was a result of Beers psychological research and his work on Operation Research. He suggested the subsequent hypothesis that there might be invariances in the behavior of individuals and that these invariances might also inform the peer group of individuals and even the total societary unit to which they belong. In the early 1950s, this theme constantly emerged in Beers operational research work in the steel industry. He used to refer to the structure of “organic systems.” The quest became to know how systems are viable (Beer 1984). One important thing to note about the cybernetic theory of organizations encapsulated in the VSM is that viable systems are recursive. Viable systems contain viable systems that can be modeled using an identical cybernetic description as the higher (and lower) level systems in the containment hierarchy (Beer 1972).
What follows is a brief introduction to the cybernetic description of the organization encapsulated in a single level of the VSM. According to Beers cybernetic model of any viable system, there are five necessary and sufficient sub-systems interactively involved in any organism or organization that is capable of maintaining its identity independently of other such organisms within a shared environment. This “set of rules” will, therefore, apply to an organism such as a human being, or to an organization consisting of human beings such as the state (Beer 1984). In broad terms Systems 1–3 are concerned with the “Inside and Now” (Beer 1984) of the organization’s operations (Beer 1972). The first sub-system of any viable system consists of those elements that produce it. These elements are themselves viable systems (Beer 1984). Taking into account that my paper focuses on the Cybersyn project, it is useful to look at the VSM as a state. According to Beer, at the limits, the citizens constitute System One of the state. This hypothesis is limited by the fact that the citizens first produce communities and companies, cities and industries, and other viable agglomerations, which are themselves all elements to be included in the state (Beer 1984). Anytime you have two or more activities being operated together; the possibility exists for them to get out of sync with each other or get in each other’s way. System Two exists as a service to coordinate common services for consistency and efficiency. System 2 represents the administrative channels and bodies that allow the primary activities in System 1 to communicate with each other (Leonard 2009). System 2 allows System 3 to monitor and co-ordinate the activities within System 1. System 3 represents the structures and controls that are put in place to establish the rules, resources, rights and responsibilities of System 1 and to provide an interface with Systems 4 and 5 (Beer 1972).
System 4 is concerned with the “Outside and Future” (Beer 1984). The term describes strategical responses to the effects of external, environmental and future demands on the organization. System Four’s role is to observe the anticipated future environment and its own states of adaptiveness and act to bring them into harmony (Leonard 2009).
System 5 is responsible for policy decisions within the organization as a whole to balance demands from different parts of the organization and steer the organization as a whole. The “fiveness” of the VSM was due to Beer’s efforts to establish the necessary and sufficient conditions of viability. The number could have been different. What could not have been otherwise was the fact of the logical closure of the viable system by System Five: only this determines an identity. Nominating the components of System Five in any application is a profoundly difficult job because the closure identifies self-awareness in the viable system. Beer often told the story of how President Salvador Allende in 1972 told him that System Five, which Beer had been thinking of as Allende himself, was, in fact, the people (Beer 1984).
In addition to the sub-systems that make up the first level of recursion, the environment is represented in the model. The presence of the environment in the model is necessary as the domain of action of the system. Algedonic alerts are alarms and rewards that escalate through the levels of recursion when actual performance fails or exceeds capability, typically after a timeout (Beer 1972).
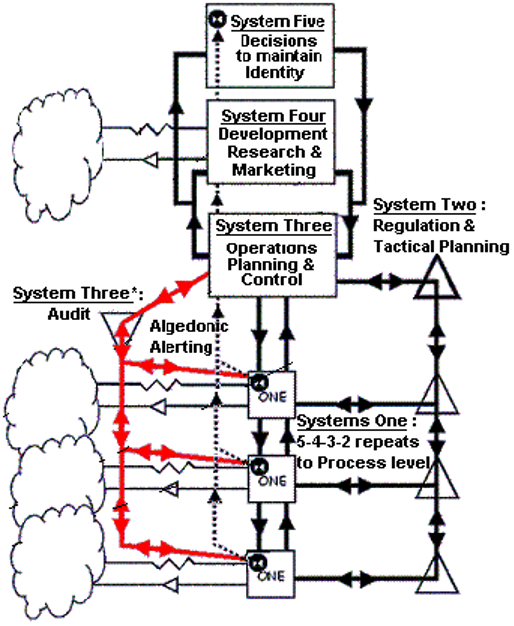
Throughout its development, the VSM has been in the process of continuous testing and verification. Meanwhile, however, the whole approach had its most significant and large-scale application during 1971–1973 in Allende’s Chile (Beer 1984).
Project Cybersyn itself was an ambitious technological project tied to an ambitious political project. It emerged in the context of Chile’s “peaceful road to socialism” (Medina 2015). Salvador Allende had won the Chilean presidency in 1970 with a promise to build a different society. His political program would make Chile a democratic socialist state with respect for the country’s constitution and individual freedoms, such as freedom of speech and freedom of the press. Giving the state control of Chile’s most important industries constituted a central plank in Allende’s platform but created management difficulties. The government had limited experience in this area (Medina 2015).
The problem of how to manage these newly socialized enterprises led a young Chilean engineer named Fernando Flores to contact Beer, the British cybernetician, and ask for advice. Flores worked for the Corporación de Fomento de la Producción (CORFO), the government agency charged with the nationalization effort. Together, Beer and Flores formed a team of Chilean and British engineers and developed a plan for a new technological system that would improve the government’s ability to coordinate the state-run economy (Medina 2015). There were several features of the project. The use of the VSM was the most important one. The team identified 12 levels of recursion from the individual worker to the country as a whole (Leonard 2009). Beer defined the Chilean state as a VSM embedded in the “world of nations”. Project Cybersyn picked out Chilean industry as a VSM. The Minister of Economy was equated with System 5 (Beer 1981). In practice, Cybersyn focused on the levels of the product line, the sector, the branch and CORFO itself. For prototyping purposes, some firms were modeled, and training was piloted for firms to provide meaningful worker information and participation and to differentiate between their roles and knowledge bases and those of the experts (Leonard 2009). The system would provide daily access to factory production data and a set of computer-based tools that the government could use to anticipate future economic behavior. It also included a futuristic operations room that would facilitate government decision-making through conversation and better comprehension of data. Beer envisioned ways to both increase worker participation in the economy and preserve the autonomy of factory managers, even with the expansion of state influence. Beer gave the system the name Cybersyn in recognition of cybernetics, the scientific principles guiding its development, and of synergy, the idea that the whole of the system was more than the sum of its technological parts. The system worked by providing the government with up-to-date information on production activity within the nationalized sector.
Factory managers transmitted data on the most important indices of production to the Chilean government on a daily basis. Regarding hardware, the system relied on a national network of telex machines that that connected the factories to the central mainframe computer (Medina 2015).

These telex machines became a historical example of the early use of collaborative software or groupware and early “internet” communication: using the system’s telex machines, the government was able to guarantee the transport of food into the city with only about 200 trucks, recouping the shortages caused by 40,000 striking truck drivers who blocked access streets towards Santiago in 1972.
The computer processed the production data and alerted the government agency in charge of the nationalization effort (CORFO) if something was wrong. Project Cybersyn also included an economic simulator, intended to give government officials an opportunity to play with different policy alternatives and, through play, acquire a heightened sense of the relationship among the various economic variables. It also included a futuristic operations room which was built in downtown Santiago.
Agreeing with Eden Medina, I suggest that Cybersyn allows us to consider that algorithmic governance can be completely different in a political, geographic and historical context different from that of northern capitalistic states (Medina 2015). If we look on present-day forms of computerized governance, for example, Amazon or Google, it becomes clear that technological development can be built on very different attempts and can have different faces.
A general problem of technological development in our society is the technology-centered idea of social change. Throughout Project Cybersyn, Beer repeatedly expressed frustration that Cybersyn was viewed as a suite of technological fixes — an operations room, a network of telex machines, an economic simulator or software to track production data — rather than a way to restructure Chilean economic management. Beer was interested in understanding the system of Chilean economic management and how government institutions might be changed to improve coordination. He viewed technology as a way to change the internal organization of Chile’s government. Eden Medina, who has investigated the case of Cybersyn, suggests moving away from thinking regarding socio-technical systems (Medina 2015).
I would go one step further in the argument. At this point, the term social-ecological system (SES) is appropriate. SES are ecological systems intricately linked with and affected by one or more social systems. Resilience is a crucial property of SES. Resilience is defined as the capacity of a system to withstand or recover from shocks. These are complex adaptive systems characterized by cross-scale interactions and feedback loops between ecological, social and economic components that often result in the reorganization of these components and non-linear trajectories of change. Consistent with Holling, hierarchies and adaptive cycles form the basis of ecosystems and social-ecological systems across scales. Together they form a so-called panarchy that describes how a healthy system can invent and experiment while being kept safe from factors that destabilize the system because of their nature or excessive exuberance. Each level is allowed to operate at its own pace. At the same time, it is protected from above by slower, larger levels but invigorated from below by faster, smaller cycles of innovation. The whole panarchy is, therefore, creative as well as conservational. The interactions between cycles combine learning with continuity. In this context, sustainability is an important factor. Sustainability is defined as the capacity to create, test and maintain adaptive capability. Development in an SES describes the process of creating, testing and maintaining opportunity. Sustainable development combines the two and refers to the aim of fostering adaptive capabilities and creating opportunities (Holling 2001).
Comparing the definition of an SES with Beer’s concept of a VSM, there are diverse similarities: both theories focus on the stability of a dynamic system. An important question is how to manage these systems to reach viability or resilience. Regarding the historical lessons of the Cybersyn project, I suggest that technological development is part of a complex pattern of factors forming a society — a human–technological complex. The role of technology in an SES is less discussed and needs more analysis. The following is the first hypothesis of my paper: algorithmic regulation containing cloud computing and Big Data are parts of a complex pattern of factors forming a society (SES) — a human–technological complex.
Now I directly deal with the second important question:
Which Measures Can Weaken the Dangers of Data Storage in a Democratic Society?
Realizing that technological investigation depends on social conditions, we have to take a look at the factors that differ concretely. If we examine technological development in our Western capitalistic states, we face two main problems: first, we have to deal with a lack of privacy protection; second, there is a lack of algorithmic transparency and democratic control. A democratic society or a socialist government does not automatically guarantee responsible handling of stored data.
Responsible handling of data is not a technical problem but is, nevertheless, a social problem. New technological innovations such as smartphones, the increased use of data-driven analytics, and the push to create smart cities and an Internet of Things all make the collection of data easier. At the same time, these innovations permit the recording of increasing volumes of human and non-human activity. Often, we adopt these data-gathering technologies before understanding their full ramifications. Looking at an example from Great Britain, as prime minister David Cameron tested the app Number 10 Dashboard on his iPad, which gave up-to-the-minute data about the UK’s economic and financial health, including GDP, bank lending, jobs and property data, as well as polling data and Twitter feeds. Polling data and Twitter feeds were defined as “political context” (Mosco 2016). One can easily imagine that Twitter feeds did not raise the GDP, but the stored data could without difficulty be abused through advertising or social control.
Such developments raise important questions about privacy and the extent to which we should expect to forfeit our privacy so that an increasingly data-driven environment can function. Privacy protection can mean the difference between a system that is centralized and abusive and one that can protect and promote human freedom. Project Cybersyn might serve as a historical example. In critical reflection, Beer overstated Cybersyn’s ability to promote freedom in Chile, but he did take pains to counteract the system’s potential for abuse by including mechanisms to protect and preserve factory autonomy. This protection was engineered into the system’s design. The government, for example, could intervene in shop-floor activities only after the software detected a production anomaly and the factory failed to resolve the anomaly within a set period (Medina 2015).
Let us take a look at the kind of data storage in Project Cybersyn. Beer proposed a system called Project Cyberstride. The system would rely on data collected from state-controlled industries. Cyberstride would use mainframe technology to make statistical predictions about future economic behavior. The system updated these predictions daily based on new data arriving from the enterprises (Medina 2011). Typically, this included data on raw materials and energy as well as data on worker satisfaction. Worker satisfaction was measured by the percentage of workers present on a given day. Operations research scientists conducted studies to determine the acceptable range of values for each index, i.e., what would be considered normal and what would be considered cause for alarm. Engineers from Chile and Britain developed statistical software to track the fluctuations in the index data and signal if they were abnormal. The software also used statistical methods to predict the future behavior of the factory and thus give government planners an early opportunity to address a potential crisis (Medina 2015). Therefore, it is possible that privacy protection is a focus of technological design.
Another important measure to gain democratic control over technology is the development of mechanisms for greater algorithmic transparency. Companies and government offices often couple large datasets with forms of algorithmic decision-making whose inner workings are shielded from public view. The use of those datasets is shielded from public view as well. We have limited knowledge of how Facebook deals with our personal information or how Google constructs our personal filter bubble of search results (Medina 2015). We have only a general—but not a complete—understanding of the factors that go into our credit-rating systems. The use and coupling of datasets taken from cell phones or computers in a criminal prosecution is the point of discussion regarding privacy protection as well as algorithmic transparency. Medina claims the need to need to develop mechanisms for greater algorithmic transparency and democratic control (Medina 2015). Obviously, research on this point is necessary. Nevertheless, the problem of algorithmic transparency is more complex. To ensure algorithmic transparency, the complexity of the algorithms should not exceed the potential user’s capacity for understanding. We are still far away from the capacity to do that. The non-transparency of software and algorithms is a problem that has existed for over 50 years. The discussion about algorithmic transparency went as far as machine learning or deep learning. Software and algorithms have been black boxes for over 50 years, even for programmers (Passig 2017). For Norbert Wiener, the father of cybernetics in 1960, one the reason for the incomprehensibility of software was our slowness in thinking. We can understand what a program does, but it may take so long that the criticism comes too late (Wiener 1960). Stanislaw Lem wrote in 1964 that systems above a certain degree of complexity are fundamentally unpredictable (Lem 1964). In 1967, Marvin Minsky called attention to the interactions of individual processes, the proliferation of the code, and the effects of the cooperation of several programmers (Minsky 1967). For Joseph Weizenbaum, it was the size of the systems, the departure of the original programmers, and the passing of time, “because the systems are a consequence of their history and history is lost” (Weizenbaum 1976).
There are causes of this incomprehensibility. The first is bugs, that is, errors in the software and hardware. They were no less frequent 50 years ago than they are today. We may now know more precisely that they are inevitable. The problem cannot be solved by merely putting better people in charge. The second unnamed cause is that code is not just what the individual programmer thinks up. Even the simplest program relies on a set of foreign code that exceeds its own by orders of magnitude. Embedded code libraries and frameworks often solve recurring tasks; software layers translate the written code into a language that the processor can process; software displays, stores or transmits all of this (Passig 2017).
Another question is what is meant by the repeatedly demanded “transparency” or “intelligibility” of algorithms? There are different possibilities for the interpretation of these words. At the lowest level, they are about whether the code is even visible. This is the case with open-source software, but usually not in the commercial sector, regardless of whether machine learning is involved. However, suppose the code is accessible. Does the requirement of transparency mean that it should be transparent for laypersons in a reasonable time? This requirement can only be fulfilled with elementary code examples (Passig 2017). Is it about the question of whether the result can be checked? There are computations whose results are comparatively easy. In an introduction to the scientific work of 1972, the following is said about “programmable electronic desktop computers:” “It is important, however, that the program is checked for accuracy. To do this, the results that the calculator prints out must be compared with the results obtained in arithmetic with pencil and paper” (Seiffert 1972). However, as soon as the computation becomes more complex, you cannot go far with pencil and paper.
The question of algorithmic transparency is complex and has a long history. Nevertheless, even if it is impossible to have full transparency, it makes sense to demand more transparency. The political environment might not change the complexity of algorithms or the fact that humans’ brains work slower than computers, but we should not forget to ask who profits from a lack of transparency.
Here, too, Project Cybersyn offers important insights. Evgeny Morozov compares Beer’s Cybersyn project to Michael Flowers’ suggestion of a concept of real-time data analysis allowing city agencies to operate in a cybernetic manner (Flowers 2013). The appeal of this approach to bureaucrats would be fairly obvious: like Beer’s central planners, they can be effective while remaining ignorant of the causal mechanisms at play (Morozov 2014). Nevertheless, according to Medina, he was not ignorant of the transparency problem. Beer believed Project Cybersyn would increase worker participation. Workers were enabled to create the factory models that formed the basis of the Cybersyn software. This integration allowed workers to connect intellectually to their work (Medina 2015). Beer argued that technology could help integrate workers’ informal knowledge into the national planning process while lessening information overload (Morozov 2014). Medina argues that it also did something else, which Beer did not acknowledge. It gave them a way to understand how this form of data-driven regulation worked. Theoretically, it allowed them to open up the black box of the computer and understand the operation of the analytical processing taking place within it (Medina 2015). Nevertheless, Project Cybersyn ended with the Pinochet coup in 1973.
We have to deal with the question of whether these measures discussed correspond with the definition of Big Data we have seen before. Morozov called Cybersyn the “socialist origin of Big Data” (Morozov 2014). I suggest it is not. Big Data as we know it signifies the storage of all data that it is possible to store and to analyze. Morozov describes the method behind Big Data as follows: “[…] collect as much relevant data from as many sources as possible, analyze them in real time, and make an optimal decision based on the current circumstances rather than on some idealized projection” (Morozov 2014). Cybersyn would have relied on the same cybernetic principles (Morozov 2014). One small problem in this context is the term relevant. Collecting data regarding the Big Data principle signifies obtaining all data possible, even if it appears irrelevant at first. Taking a look at the kind of data stored and analyzed by Cybersyn described above, it becomes clear that not all kinds of data were stored. Working with Big Data, Cybersyn would have stored how often workers use the lavatory, made a profile with the help of their mobile phones, and so on. A comparison with Cameron’s app Number 10 Dashboard makes the difference even clearer.
My second interim result is that Big Data is a product of our capitalistic society oriented toward profits. For scientific research, we do not have to handle all the random data we get. The technological development allows us to work with increasingly complex data. This advance is a great scientific challenge, but the big Vs that I described are not necessarily useful for scientific analysis. Big Data mainly works in favor of great companies using the information to sell their products, or it may be used by autocratic governments. This lack can only be valuable if organizations handling data support the individuals they are addressing. In this case, the power of the individuals and democratic control can increase considerably.
Now I am going to deal with my last question.
How Much Data-Driven Governance Do Democracy and Political Participation Need?
In addition to his work on Project Cybersyn, Stafford Beer asked how cybernetics might help the state to respond quickly to the demands of the people. Regarding the fact that television ownership had increased in the 1970s in Chile (123,000 to 500,000), Beer proposed building a new form of real-time communication via TV that would allow the people to communicate their feelings to the government (Medina 2011). The increasing purchasing power in the first year of Allende’s government was a result of his economic program. The government had developed a broad outline for structural reform. One element was a Keynesian-based economic recovery plan initiated by the Minister for the Economy Pedro Vuskovic, a sort of Chilean New Deal. It was based on the redistribution of wealth and an attempt to partially freeze rising commodity prices (the 1970 price increase stood at 35%). If one takes into account the salary increases introduced on 1 January 1971 and the bonuses and increases in welfare benefits, the salaries of the lowest-paid workers and peasants may have risen by as much as 100%. In consequence, a spending fever hit the lowest income groups, and industrial production suddenly took off again (production increased by 10% a year in 1971 and 1972). Commercial activity revived and unemployment dropped off. Nevertheless, all of these reforms provoked dissent, which slowed down the social reconstruction of the country (Compagnon 2004).
Beer called his system Project Cyberfolk. He planned to build a series of so-called algedonic meters capable of measuring how happy Chileans were with their government. Beer proposed building a series of algedonic meters capable of measuring the happiness of Chilean citizens about their government in real time. These algedonic meters would not ask questions. The users simply moved a pointer on a dial somewhere between total dissatisfaction and total happiness. Users could construct their scale of happiness. This construction was reminiscent of Beer’s attention to autonomy and broad participation. These meters could be installed in any location with a television set. Cyberfolk was never realized. Beer commissioned several prototype meters and used them in small-group experiences (Medina 2011).
Beyond the basic problem that 500,000 television sets in Chile were still a low number, it is easy to imagine how a government could abuse such a device or partisan groups might manipulate them.
Looking at political uses of today’s cloud, it seems to have little to do with practicing democracy, civic participation or activism. As an example, I refer to Barack Obama’s campaign’s use of cloud-computing and Big Data analyses in the presidential elections 2012 to identify potential voters and deliver enough of them to the polls and exceed many pundits’ expectations. The campaign built more than 200 apps that ran on Amazon Web Services (Mosco 2016).
Obviously, political participation does not need Big Data. Nevertheless, as cybernetic history shows, in a human–technological complex, technical measures and cloud computing can be useful to support civic participation and activism.
As an example of civic participation, I chose the participatory budget (PB) in Brazil. I chose this example because there are some political similarities to the case of Chile on a local level. Of course, a direct comparison is not possible. The establishment of the PB in Porto Alegre was an example of a process of re-democratization that overtook Latin America in the 1980s. Many countries shared a common agenda regarding democracy and its institutions: they were struggling to build or rebuild their democratic institutions with an agenda that focused mainly on fighting corruption, improving access to government and strengthening governmental accountability. These experiences are unusually diverse in countries characterized by deep-rooted political, social, economic and regional disparities such as Brazil (Souza 2001). Nevertheless, we also deal with the election of a socialist party and small economical resources.
Brazil is an example of both re-democratization and decentralization. Regarding participation, the 1988 constitution provided several mechanisms that allowed grassroots movements to take part in some decisions and to oversee public matters, especially at the local level (Souza 2001). The financial autonomy afforded to Brazilian municipalities under the 1988 constitution and the spoils system meant that the mayor had discretion over a significant and guaranteed resource stream and was allowed to make strategic senior appointments to support the development of participatory governance. PB challenged the traditional role of the city councilors and the legislative branch (Cabannes 2004).
The PB was established in Porto Alegre by the incoming Workers’ Party mayor who had the explicit intention of designing a participatory process that challenged the clientelism and corruption endemic within Brazilian political culture and legitimized redistributive policies. In the 1990s, the city of Porto Alegre in southern Brazil won international renown with its innovative policies. The centerpiece of the new policy involved the population in planning the city budget: participatory budgeting. One has to keep in mind that it was not only Porto Alegre, or other cities governed by leftist parties, that embarked on a policy of increasing local revenue but also several municipalities across Brazil (Souza 2001).
The main functions of the PB, especially in Porto Alegre or Belo Horizonte, are described and analyzed by various authors (Sánchez 2002; Fedozzi 2001). Practices differed in cities and communities over the years, but I regard as important for my study some common elements of direct and representative democracy, as follows:
- Citizens received basic information about the city budget in meetings at the district level. Delegates selected from the people attending these meetings drew up a list of priorities for projects in the forthcoming budget, in consultation with the general public and the administration.
- The next step was for all those taking part to vote on assigning priorities to projects and to elect two delegates from each district to the Conselho do Orçamento Participativo (COP).
- Alongside the district assemblies, issue-related assemblies were also set up to handle city-wide topics; these nominated two delegates each to the COP, too.
- By the directives from the district and issue-related assemblies, the COP drew up a draft budget plus investment plan and submitted these to the city council for assessment and final decision. The COP was also responsible for working out the rules for the process of planning the next budget. These rules incorporated allocation formulae developed specially to ensure even treatment of poor and rich districts. The structures of the participatory budget were largely developed autonomously; the intention was to revise these structures year by year.
One might ask what this example of civic activism, which demands face-to-face meetings, has to do with the human–technological complex. First, we have to consider that personal meetings are absolutely necessary for political activism and democratic life. However, in the last few years, so-called digital participatory budgets were installed in different cities. Currently, some of the municipalities in Brazil are going beyond the traditional processes of participation such as the PB and have started using information and communication technologies (ICTs) such as the internet in these local participatory processes, so called digital participatory budgeting (DPB). DPB is an online space for discussions with society on local budget-allocation issues and priorities. Such platforms exist both as an integral part of face-to-face participatory budgeting as well as exclusively digital experiences (Matheus et al. 2010). Digital participatory budgeting is more recent and, until 2016, was less frequently used in Brazil when compared to face-to-face participatory budgeting. The first experiments took place in 2001 in the city of Porto Alegre, Rio Grande do Sul, and in Ipatinga, Minas Gerais. Data from 2014 shows that 37 such platforms were operating in Brazil at the time. Even if digital inequality varies across Latin American countries and within different areas of those countries, innovations based on ICT tools have been growing all over the region. Many scholars promote e-participation as very positive. The Innovations for Democracy in Latin America (LATINNO) Project at the WZB Berlin Social Science Center, which investigates democratic innovations that have evolved in 18 countries across Latin America since 1990, has just completed a study of new digital institutional designs that promote e-participation aimed at improving democracy. The LATINNO project is the first comprehensive and systematic source of data on new forms of citizen participation evolving in Latin America. The research focused on Brazil, Colombia, Mexico and Peru—countries with different political and social backgrounds, varied population sizes and different levels of internet connectivity. The findings not only disclose common patterns among these countries but also indicate trends that may reveal how digital democracy may evolve in the region in coming years. Taken together, Brazil, Colombia, Mexico, and Peru created 206 innovations for e-participation between 2000 and 2016, 141 of which are still active in 2017. Brazil and Mexico are the countries with the highest number of digital innovations (73 and 71, respectively), followed by Colombia (32) and Peru (30). Given that Brazil and Mexico are both large countries with large populations, one could expect their number of digital innovations to be higher. The number of innovations created in 2015 is five times higher than the number implemented in 2010 (the year after which, about 90% of all cases have been initiated). Although most new digital spaces for e-participation are recent and new technologies quickly become old, the research group argues that innovations have overall been demonstrating a reasonable level of sustainability (Pogrebinschi 2017). At this point, I see another commonality with Project Cybersyn. Stafford Beer and his team had to work with only one mainframe computer and telex machine. Sustainability must be one of the main focuses in IT development to ensure responsible handling of data. In this context, more thought has to be given toward how we can extend the life of older technologies (Medina 2015).
The process of digital democratic innovations has connected the concepts of electronic governance and electronic government intimately, a theme that is under construction because of the novelty of the subject and area of study. There are differences between the limits of these concepts, and some authors call’s for electronic governance will be for others understood as electronic government, and vice-versa. Regardless of the theoretical discussions that are underway, electronic government and electronic governance are widely seen as a tool with many possibilities to support changes in government and even the transformation of society itself. There are fundamental differences between electronic government and electronic governance. The concept of electronic government is seen largely as the government’s relationship with the company regarding the provision of services via electronic tools. These services might be the use of the internet, the intensive application of information technology in the process of services and the relationship of governments to citizens for electronic brokerage. That is, electronic government is often supported by a side whose focus is more on providing information than on an interaction between government and society. The concept of electronic governance goes beyond electronic services delivery, and technological improvements in public administrations such as several authors describe for electronic government and electronic governance. According to Matheus, Ribeiro, Vaz and de Souza, electronic governance extends to a broader issue. Electronic governance concerns the relationship between citizens and the governmental body in the current context of democratization. Governance has several implications, being understood as the state capacity to implement, efficiently and effectively, the decisions that are taken. So, the concept of governance refers to decision-making processes and government action, and its relationship with citizens. This relationship is based on control and accountability, transparency of data and information, and participation in decision-making both in the formulation and monitoring phases of public policies (Matheus et al. 2010).
Looking back at project Cybersyn again, I suggest that Stafford Beer explored electronic government as well as electronic governance without being aware of these terms. Cybersyn would have offered a service of providing information as well as the possibility of worker’s participation. Cyberfolk, far from perfect, can be seen as an early concept of electronic governance.
Electronic governance in Brazil is somewhat troubled. We have a society that due to social and cultural conditions exists without the benefits of technology. One has to consider a lack of infrastructure and services for those citizens who cannot pay (another similarity to the case of Chile). Nevertheless, in some areas, technological feasibility, resources and skilled workers provide services with deep social inequality to the power of social movements and civil society organizations (Matheus et al. 2010).
A case study from Matheus, Ribeiro, Vaz and de Souza presented the use of ICTs in participatory budgeting on the following occasions: to monitor the participatory budget; to collect the proposals that would be taken for voting in participatory budgeting; and the participatory budgeting vote (Matheus et al. 2010).
As shown in Table 1, different cities use different methods of monitoring the PB via the internet. The earliest digital measures of monitoring PBs can be found in the city of Porto Alegre, Brazil. Using the internet to monitor the PB supports the promotion of social control. Besides, by allowing searches of the database of the site, monitoring the PB allowed the monitoring of citizens through information sent by email to the government in the PB site. According to the authors, the use of ICTs would not only expand the number of people tracking and monitoring, since local citizens, representatives of PB and community leaders are monitoring in person and disseminating information via the internet so that everyone has access to the progress of the PB. Only the city of Ipatinga was using the internet to gather proposals for the participatory budgeting vote. In the other places, decisions are still taken by the popular assemblies (Porto Alegre, Recife, Bella Vista and Miraflores) or by the city hall (Belo Horizonte) (Matheus et al. 2010).

The reactions of citizens to ICT are entirely different. In their analysis of the DPB experience in Belo Horizonte from 2014, Júlio Cesar Andrade de Abreu and José Antonio Gomes de Pinho conclude that democratic sentiments and the meaning of e-participation ranged from large impulses of democratic hope up to disbelief in digital participation. The authors analyzed three episodes from 2006, 2006 and 2011 of DPB in Belo Horizonte. During this period, messages and manifestations of the citizens who were participating were collected (Abreu and Pinho 2014).
This case study supports my last hypothesis: in an SES, groupware, cloud, or technical development can support democratic participation if it is seen as a socio-technological complex. Nevertheless, it also may be abused. Even more than Project Cybersyn, the PB and DPB and their relationship in political participation show the complex pattern of political activism by people formed by face-to-face assemblies, written papers, demonstrations, bureaucracy and technology. Taking a look at the data collected in the different forms of digital participatory budget, the importance of responsible handling of data has to be highlighted again. The datasets regarding PB might be “big”, but contain less random data. Monitoring PB, even online voting, does not need data from fitness trackers of the participants nor their Twitter feeds. Democratic participation might be strengthened by technology, but never by Big Data in the sense of collecting everything possible.
Conclusions
Big Data, cloud computing and algorithmic regulation are not only forms of data collection or technological components. Discussions about technological developments should not be reduced to technology. It is not about single technological components; it is about the social, political, economic and technical. It is about the role of technology in the complex pattern of society. The SES theory might help in the interpretation of this complex pattern. Ecological systems are not only linked to social systems but socio-technological systems. Technology might be seen as a factor that can support or weaken the resilience of a socio-ecological system (SES) while it is influenced by other factors of the SES. Looking at the SES theory, it is important to keep in mind that society cannot be reduced to a management system. I suggest that fact as a critical point regarding SES theory as well as Beers thinking of management as a system.
Cybersyn serves as an historical example how algorithmic regulation can change in societies other than northern capitalistic states. Nevertheless, it had limitations. Planned to support companies and workers’ participation, it may have disempowered workers by coding their knowledge in software used by the central state (Medina 2015). Looking at Cyberfolk, which was never realized, there are even more contradictions. It is easy to imagine how Cyberfolk could collect information from people regarding Big Data defined above. Cyberfolk also leaves out the most important components of political life and participation: communication, face-to-face meetings, and assemblies.
According to Judith Butler, assemblies of physical bodies have an expressive dimension which is not reducible to speech, since their physical presence affect the outcome of their gatherings. Butler links assembly with precarity by pointing out that a body suffering under conditions of precarity persists and resists, and that mobilization brings out this dual dimension of corporeal life, just as assemblies make visible and audible the bodies that require basic freedoms of movement and association. By enacting a form of radical solidarity in opposition to political and economic forces, a new sense of “the people” emerges that is interdependent, capable of grievances, precarious and persistent (Butler 2015). No doubt technological inventions cannot replace face-to-face assemblies. No virtual space can replace real space. A system like Cyberfolk would have never managed the political life of Chileans. Nevertheless, information and communication technology can support citizen’s movements. The case study of the PBs and DPB might serve as an example for the interconnection of assemblies and information and communication technologies. There is not a central system regulating PB. There are different technical measures in the PBs, resulting in different forms of participation that support the discussions and voting of the citizens. One might argue that technical equipment is not available for many people for economic reasons. It is important to keep in mind that a predominance of digital innovation in participation processes might force social division; this is the face of digital participation in capitalistic societies. Nevertheless, digital and technical support of face-to-face assemblies offers access to information and possibilities for participation for many people. Placed in a socio-technological system, technical innovation might be an important measure to support political activism and democratic participation.
References
Beer, Stafford. 1972. Brain of the Firm. London: The Penguin Press. [Google Scholar]
Beer, Stafford. 1981. Brain of the Firm, 2nd ed. Chichester, New York, Brisbane and Toronto: John Wiley & Sons. [Google Scholar]
Beer, Stafford. 1984. The Viable System Model: Its Provenance, Development, Methodology and Pathology. The Journal of the Operational Research Society35: 7–25. [Google Scholar] [CrossRef]
Beer, Stafford. 1994. Designing Freedom. Chichester: Wiley. [Google Scholar]
Butler, Judith. 2015. Notes toward a Performative Theory of Assembly. Cambridge: Harvard University Press. [Google Scholar]
Cabannes, Yves. 2004. Participatory Budgeting: A Significant Contribution to Participatory Democracy. Environment and Urbanization16: 27–46. [Google Scholar] [CrossRef]
Compagnon, Olivier. 2004. Popular Unity: Chile, 1970–1973. In Encyclopedia of Labor History Worldwide. St. James Press: Available online: https://halshs.archives-ouvertes.fr/halshs-00133348(accessed on 5 December 2017).
De Abreu, Júlio Cesar Andrade, and José Antonio Gomes de Pinho. 2014. Sentidos e significados da participação democrática através da Internet: Uma análise da experiência do Orçamento Participativo Digital. Revista de Administração Pública48: 821–46. [Google Scholar] [CrossRef]
Elgendy, Nada, and Ahmed Elragal. 2014. Big Data Analytics: A Literature Review Paper. Paper presented at Advances in Data Mining. Applications and Theoretical Aspects: 14th Industrial Conference (ICDM 2014), St. Petersburg, Russia, July 16–20. Conference Paper in Lecture Notes in Computer Science August 2014. [Google Scholar] [CrossRef]
Espejo, Raul, and Alfonso Reyes. 2011. Organizational Systems: Managing Complexity with the Viable System Model. Berlin and Heidelberg: Springer Science & Business Media. [Google Scholar]
Fedozzi, Luciano. 2001. Orçamento participativo. reflexões sobre a experiência de Porto Alegre. Porto Alegre: Tomo Editorial. [Google Scholar]
Flowers, Michael. 2013. Beyond Open Data: The Data-Driven City. In Beyond Transparency: Open Data and the Future of Civic Innovation. Edited by Brett Goldstein and Lauren Dyson. San Francisco: Code for American Press, pp. 185–99. [Google Scholar]
Holling, Crawford S. 2001. Understanding the Complexity of Economic, Ecological, and Social Systems. Ecosystems4: 390–405. [Google Scholar] [CrossRef]
Laney, Douglas. 2001. 3D Data Management: Controlling Data Volume, Velocity, and Variety. In Application Delivery Strategies. Stamford: META Group. [Google Scholar]
Lem, Stanislaw. 1964. Summa Technologiae. First Published in 1964. Minneapolis: University of Minnesota Press. [Google Scholar]
Leonard, Allenna. 2002. Stafford Beer: The Father of Management Cybernetics. Cybernetics and Human Knowing9: 133–36. [Google Scholar]
Leonard, Allenna. 2009. The Viable System Model and Its Application to Complex Organizations. Systemic Practice and Action Research22: 223–33. [Google Scholar] [CrossRef]
Magoulas, Roger, and Ben Lorica. 2009. Introduction to Big Data. Release 2.0. Sebastopol: O’Reilly Media. [Google Scholar]
Matheus, Ricardo, Manuella Maia Ribeiro, Jose Vaz, and Cesar Souza. Case Studies of Digital Participatory Budgeting in Latin America: Models for Citizen Engagement. Paper presented at 4th International Conference on Theory and Practice of Electronic Governance (ICEGOV 2010), Beijing, China, October 25–28. [Google Scholar]
Medina, Eden. 2011. Cybernetic Revolutionaries: Technology and Politics in Allende’s Chile. Cambridge: MIT Press. [Google Scholar]
Medina, Eden. 2015. Rethinking Algorithmic Regulation. K Kybernetes44: 1005–19. [Google Scholar] [CrossRef]
Minsky, Marvin. 1967. Why Programming Is a Good Medium for Expressing Poorly Understood and Sloppily Formulated Ideas. In Design and Planning II. Computers in Design and Communication. Edited by Martin Krampen and Peter Seitz. New York: Hastings House, pp. 117–21. [Google Scholar]
Morozov, Evgeny. 2014. Project Cybersyn and the Origins of the Big Data Nation. 3QuarksDaily, October 13. [Google Scholar]
Mosco, Vincent. 2016. To the Cloud: Big Data in a Turbulent World. New York: Routledge. [Google Scholar]
O’Reilly, Tim. 2013. Open Data and Algorithmic Regulation. In Beyond Transparency: Open Data and the Future of Civic Innovation. Edited by Brett Goldstein and Lauren Dyson. San Francisco: Code for American Press, pp. 289–300. [Google Scholar]
Passig, Kathrin. 2017. Fünfzig Jahre Black Box. Merkur, November 23. [Google Scholar]
Pogrebinschi, Thamy. 2017. Digital Innovation in Latin America: How Brazil, Colombia, Mexico, and Peru Have Been Experimenting with E-Participation. Democracy and Democratization (Blog). June 7. Available online: https://democracy.blog.wzb.eu/tag/e-democracy/(accessed on 5 December 2017).
Sánchez, Félix Ruiz. 2002. Orçamento participativo: Teoria e practica. São Paulo: Cortez. [Google Scholar]
Seiffert, Helmut. 1972. Einführung in das Wissenschaftliche Arbeiten. Braunschweig: Vieweg. [Google Scholar]
Souza, Celina. 2001. Participatory Budgeting in Brazilian Cities: Limits and Possibilities in Building Democratic Institutions. Environment and Urbanization13: 159–84. [Google Scholar] [CrossRef]
Ward, Jonathan Stuart, and Adam Barker. 2013. Undefined By Data: A Survey of Big Data Definitions. arXiv, arXiv:1309.5821. [Google Scholar]
Weizenbaum, Joseph. 1976. Computer Power and Human Reason: From Judgment to Calculation. New York: W.H. Freeman & Co. Ltd. [Google Scholar]
Wiener, Norbert. 1948. Cybernetics, or Control and Communication in the Animal and the Machine. Cambridge: MIT Press. [Google Scholar]
Wiener, Norbert. 1960. Some Moral and Technical Consequences of Automation. Science131: 1355–58. [Google Scholar] [CrossRef] [PubMed]
…………………………………………………………………………………………………………….………………
Source: This article was originally published in the Special Issue Big Data and the Human and Social Sciences. Soc. Sci. 2018, 7(4), 65; https://doi.org/10.3390/socsci7040065. It is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
…………………………………………………………………………………………………………………..………………
 [*] Katharina Loeber (kaloeber@googlemail.com) holds a PhD in History from the University of Cologne (Germany). She was a lecturer, over the last two years and until very recently, for British and American history politics, at the University of Kassel (Germany), Department of British and American History. She wrote so far two books: Human Ecology. Engineering White Supremacy in Twentieth Century South Africa. Böhlau Verlag, Wien, Köln, Weimar, 2019, and Der Niedergang des Chilesalpeters. Chemische Forschung-militärische Interessenökonomische Auswirkungen. Schriftenreihe Deutsch-Lateinamerikanische Forschung, Wissenschaflicher .Verlag Berlin, Köln, Berlin, 2010.
[*] Katharina Loeber (kaloeber@googlemail.com) holds a PhD in History from the University of Cologne (Germany). She was a lecturer, over the last two years and until very recently, for British and American history politics, at the University of Kassel (Germany), Department of British and American History. She wrote so far two books: Human Ecology. Engineering White Supremacy in Twentieth Century South Africa. Böhlau Verlag, Wien, Köln, Weimar, 2019, and Der Niedergang des Chilesalpeters. Chemische Forschung-militärische Interessenökonomische Auswirkungen. Schriftenreihe Deutsch-Lateinamerikanische Forschung, Wissenschaflicher .Verlag Berlin, Köln, Berlin, 2010.